Содержание
Как запросить выписку из ЕГРЮЛ. Контур.Фокус для абонентов Контур.Экстерн. — Контур.Экстерн
Общая информация
Сервис Контур.Фокус предназначен для получения информации о контрагентах. Пользователям Контур.Экстерна доступны следующие данные:
- поиск,
- данные ЕГРЮЛ/ЕГРИП,
- запрос на выписку,
- бухформы.
Абоненты системы Контур.Экстерн могут запрашивать неограниченное количество выписок в течение годового обслуживания. Эта информация помогает сделать вывод о благонадежности контрагента. Контур.Фокус несет информационно-ознакомительный характер. Все данные взяты из открытых реестров.
Работа в сервисе
Для входа в сервис необходимо перейти на портал по адресу https://kontur.ru, нажать кнопку «Войти в сервисы» и выбрать блок «Фокус», либо воспользоваться прямой ссылкой для входа https://focus.kontur.ru.
Перейти в Контур.Фокус из системы Контур. Экстерн можно с помощью меню «Контур» — «Фокус Проверка контрагентов».
Экстерн можно с помощью меню «Контур» — «Фокус Проверка контрагентов».
Поиск контрагентов
На главной странице Контур.Фокус находится основная строка поиска. Найти контрагента можно по ИНН, ОГРН, названию, адресу или ФИО.
- Поиск производится только по головным организациям, в сервисе нет обособленных подразделений и филиалов — согласно законодательству, они не являются самостоятельными юридическими лицами.
- В сервисе нет реестра иностранных организаций.
- В выписке ЕГРЮЛ не отображаются КПП Крупнейших налогоплательщиков. Есть информация только об основном КПП.
В результате поиска откроется страница, где можно настроить необходимый регион и выбрать отрасль работы контрагента.
Карточка организации
Общая информация состоит из:
- наименования организации,
- реквизитов,
- контактов,
- даты образования/ликвидации,
- адреса,
- руководителей,
- видов деятельности,
- регистрации во внебюджетных фондах.


Источниками сведений являются: ФНС, ЕГРЮЛ/ЕГРИП и Росстат. Информация обновляется ежедневно
Выписки ЕГРЮЛ/ЕГРИП
Возможность получать выписки ЕГРЮЛ и ЕГРИП предоставляются абонентам, подключенным по тарифным планам, включающим разрешение «Доступ к федеральным ресурсам» («Проверка контрагентов»).
За подробной информацией о доступных по тарифному плану услугах следует обращаться в сервисный центр по месту подключения.
Выписка ЕГРЮЛ/ЕГРИП, полученная в Контур.Фокус может быть двух видов — информационная и юридически значимая. Юридически значимая выписка содержит визуализацию подписи ФНС России.
Откуда берутся выписки?
Выписки формируются на основании данных, содержащихся в реестрах ЕГРЮЛ и ЕГРИП. Эти реестры являются федеральными информационными ресурсами, которые заполняются и актуализируются Федеральной Налоговой Службой и ее территориальными органами. Компания СКБ Контур получает доступ к ресурсам на платной основе, согласно утвержденному порядку, и не несет ответственности за содержание и полноту выписок.
Компания СКБ Контур получает доступ к ресурсам на платной основе, согласно утвержденному порядку, и не несет ответственности за содержание и полноту выписок.
Как получить выписку?
В строке поиска ввести известные данные об искомой организации (например, ИНН, ОГРН, название, адрес, ФИО руководителя).
Нажать кнопку с лупой (Найти). В списке найденных организаций необходимо выбрать нужную, щелкнув по ее названию.
Откроется карточка организации. Для просмотра выписки кликните по ссылке «Сформировать».
Чтобы получить выписку с подписью ФНС, необходимо нажать «Запросить с подписью ФНС»
Просмотр полученной выписки
После нажатия на ссылку «Сформировать выписку» она появится в соседней вкладке в формате PDF.
Финансовое состояние
Финансовое состояние — это бухформы, графики и финансовый анализ, сформированные на основе бухформ. Ежегодно организации сдают бухгалтерскую статистическую отчетность. Эти данные попадают в региональную статистику, а дальше — в Росстат. В соответствии с Постановлением Правительства РФ № 420 ЗАО «ПФ «СКБ Контур», как заинтересованное лицо, получает открытую информацию о бухгалтерской отчетности юридических лиц. После получения эти данные попадают на страницы Контур.Фокуса.
Ежегодно организации сдают бухгалтерскую статистическую отчетность. Эти данные попадают в региональную статистику, а дальше — в Росстат. В соответствии с Постановлением Правительства РФ № 420 ЗАО «ПФ «СКБ Контур», как заинтересованное лицо, получает открытую информацию о бухгалтерской отчетности юридических лиц. После получения эти данные попадают на страницы Контур.Фокуса.
Бухгалтерская статистическая отчетность за год появляется в открытом доступе в августе-сентябре года, следующего за отчетным.
Сервис «Светофор»
У абонентов Контур.Экстерн за 92 дня до окончания срока обслуживания открывается доступ в экспресс сервис для проверки контрагентов «Светофор». Сервис автоматически проверяет организации (или ИП) и сигнализирует о нахождении информации, требующей повышенного внимания и изучения. Подробная информация о сервисе в инструкции.
Подключение полнофункционального Контур.Фокуса
Полнофункциональная версия Контур. Фокуса содержит более обширную информацию об организациях. Помимо данных ЕГРЮЛ/ЕГРИП и бухформ становится доступной такая информация, как арбитражные дела, сообщения о банкротстве, членство в ТПП РФ, госконтракты, особые адреса и т д. По вопросу подключения полнофункциональной версии Контур.Фокус следует обращаться в свой сервисный центр либо на электронную почту [email protected].
Фокуса содержит более обширную информацию об организациях. Помимо данных ЕГРЮЛ/ЕГРИП и бухформ становится доступной такая информация, как арбитражные дела, сообщения о банкротстве, членство в ТПП РФ, госконтракты, особые адреса и т д. По вопросу подключения полнофункциональной версии Контур.Фокус следует обращаться в свой сервисный центр либо на электронную почту [email protected].
проверка контрагента по ИНН в системе СПАРК
Обновить браузер
Обновить браузер
Возможности
Интеграция
О системе
Статистика
Контакты
CfDJ8BWwtsnsfW1DmJmxNv0KRToWZ4rnVdDPO79W1Dpypa-hB00MmjEVwTaucESoLUbV1WoBF0yC42hyFeaYCF9ifK2JQmEDyXmvjZwerR8ZgciKzeyLgSFLNJEh4OE7fUey-7UhvoKnX_cbIYEPiFWejEc
Описание поисковой системы
энциклопедия поиска
ИНН
ОГРН
Санкционные списки
Поиск компаний
Руководитель организации
Судебные дела
Проверка аффилированности
Исполнительные производства
Реквизиты организации
Сведения о бенефициарах
Расчетный счет организации
Оценка кредитных рисков
Проверка блокировки расчетного счета
Численность сотрудников
Уставной капитал организации
Проверка на банкротство
Дата регистрации
Проверка контрагента по ИНН
КПП
ОКПО
Тендеры и госзакупки
Поиск клиентов (B2B)
Юридический адрес
Анализ финансового состояния
Учредители организации
Бухгалтерская отчетность
ОКТМО
ОКВЭД
Сравнение компаний
Проверка товарных знаков
Проверка лицензии
Выписка из ЕГРЮЛ
Анализ конкурентов
Сайт организации
ОКОПФ
Сведения о регистрации
ОКФС
Филиалы и представительства
ОКОГУ
ОКАТО
Реестр недобросовестных поставщиков
Рейтинг компании
Проверь себя и контрагента
Должная осмотрительность
Банковские лицензии
Скоринг контрагентов
Лицензии на алкоголь
Мониторинг СМИ
Признаки хозяйственной деятельности
Репутационные риски
Комплаенс
Безлимитные онлайн-выписки позволят выполнить требования должной осмотрительности
Выписка из Единого государственного реестра юридических лиц (ЕГРЮЛ) или Единого государственного реестра индивидуальных предпринимателей (ЕГРИП) является важным документом для получения информации о любых изменениях в деятельности компании. Всем пользователям СПАРКа доступна функция безлимитного заказа выписок из ЕГРЮЛ и ЕГРИП для проверки информации о государственной регистрации партнера, а также в целях выполнения требований налоговых органов о проявлении должной осмотрительности при выборе контрагента.
Всем пользователям СПАРКа доступна функция безлимитного заказа выписок из ЕГРЮЛ и ЕГРИП для проверки информации о государственной регистрации партнера, а также в целях выполнения требований налоговых органов о проявлении должной осмотрительности при выборе контрагента.
Выписка из СПАРКа будет содержать в себе подробные регистрационные данные компании, информацию об изменениях в учредительных документах компании за время её существования, статусе компании, её учредителях, акционерах и др.
Заказанные выписки из ЕГРЮЛ могут быть автоматически направлены на Вашу электронную почту.
Демо-доступ
Бесплатный просмотр 5 компаний
Вам могут быть интересны
Все возможности
Дополнить данные о своей компании
Заявка на демо-доступ
Заявки с указанием корпоративных email рассматриваются быстрее.
Вход в систему будет возможен только с IP-адреса, с которого подали заявку.
Компания
Телефон
Вышлем код подтверждения
Эл. почта
Вышлем ссылку для входа
Нажимая кнопку, вы соглашаетесь с правилами использования и обработкой персональных данных
Выписка из ЕГРЮЛ — Контур.Фокус
Содержание:
Сервис Контур.Фокус позволяет в один клик получить свежую выписку из Единого государственного реестра юридических лиц (ЕГРЮЛ). Выписка из ЕГРЮЛ позволяет иметь актуальную информацию по интересующим компаниям, также она может быть представлена в качестве доказательств в ходе судебных или налоговых разбирательств, если нужно подтвердить наличие определённой информации в выписке на конкретную дату. Полезными для оценки и анализа контрагентов могут оказаться и такие возможности, как финансовый анализ, лизинг движимого и недвижимого имущества, пользовательские списки.
Структура выписки из ЕГРЮЛ
Сформированная выписка из ЕГРЮЛ содержит в себе следующие разделы:
- Наименование. Указывается полное и сокращённое название юридического лица, а также ГРН и дата внесения соответствующей записи.
- Организационно-правовая форма. В отношении международных компаний и фондов.
- Адрес (место нахождения). Отражаются сведения о полном почтовом адресе (индекс, субъект РФ, город и прочее).
- Сведения о регистрации. Информация о способе образования, номер ОГРН и дата присвоения.
- Сведения о регистрирующем органе по месту нахождения юридического лица. Наименование и адрес территориального органа Федеральной налоговой службы.
- Сведения о прекращении. Способ прекращения, дата и наименование территориального органа ФНС, сделавшего соответствующею запись.
- Сведения о состоянии юридического лица. Предприятие в стадии ликвидации, банкротства.
- Сведения об учёте в налоговом органе. Сведения об ИНН/КПП, дате присвоения, а также наименование территориального органа ФНС.
- Сведения о регистрации в качестве страхователя в терр. ПФР. Указывается присвоенный номер, дата регистрации, а также наименование территориального органа ПФР.
- Сведения о регистрации в качестве страхователя в терр. ФСС. Регистрационный номер, дата присвоения, наименование территориального органа ФСС.
- Сведения об уставном капитале (складочном капитале, уставном фонде, паевых взносах). Указывается вид капитала и его стоимостное выражение.
- Сведения о лице, имеющем право без доверенности действовать от имени юридического лица. Развёрнутое ФИО, ИНН, должность, дата внесения соответствующей записи.
- Сведения об учредителях (участниках) юридического лица. Отражается развёрнутое ФИО, ИНН, номинальная стоимость доли и её размер в процентах.
- Сведения о видах экономической деятельности по ОКВЭД. Отражается информация об основном виде деятельности, а также обо всех дополнительных с указанием дата внесения соответствующих записей в реестр.
- Сведения о держателе реестра акционеров акционерного общества. Указывается полное наименование держателя и номер ОГРН.
- Сведения о лицензиях. Представлена общая информация обо всех имеющихся лицензиях с указанием даты получения и номера, периода действия, вида деятельности и лицензирующего органа.
- Сведения о правопреемнике или правопредшественнике. Полное наименование организации-предшественника или правопреемника, с указанием номеров ИНН и ОГРН.
- Сведения о филиалах. Указывается развёрнутый почтовый адрес в отношении каждого имеющегося филиала.
- Сведения о прохождении реорганизации. Запись о начале процедуры реорганизации
- Сведения о процессе уменьшения уставного капитала. Применяется к хозяйствующим обществам.
- Сведения о записях, внесённых в ЕГРЮЛ. Информация о каждом внесении изменений, с указанием даты, причины, наименования документа (при наличии).
 Предприятие в стадии ликвидации, банкротства.
Предприятие в стадии ликвидации, банкротства. Отражается развёрнутое ФИО, ИНН, номинальная стоимость доли и её размер в процентах.
Отражается развёрнутое ФИО, ИНН, номинальная стоимость доли и её размер в процентах.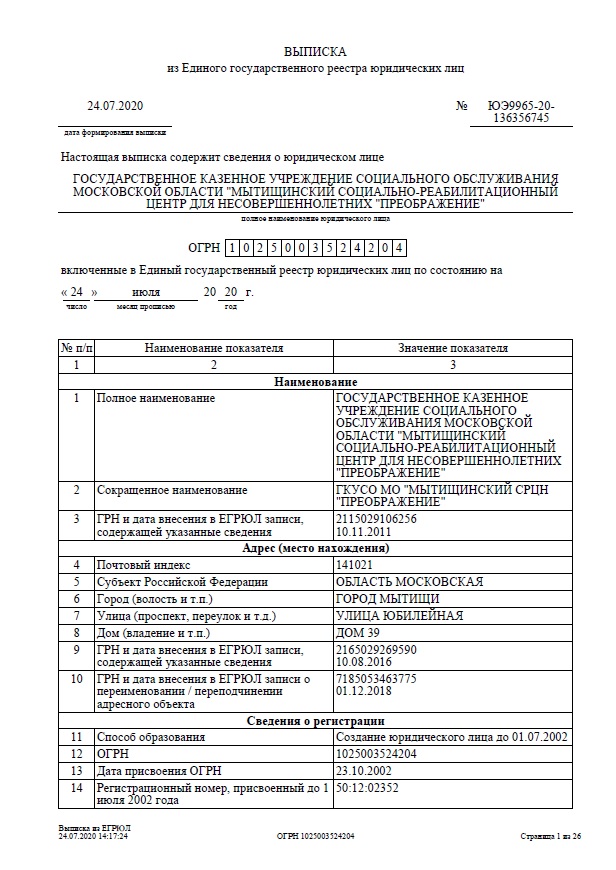 Запись о начале процедуры реорганизации
Запись о начале процедуры реорганизацииТакже в Едином государственном реестре должен иметься подлинник или нотариально заверенная копия учредительного документа.
Статусы юр.лица
Юридическое лицо может иметь один из перечисленных ниже статусов (1 и 7 раздел выписки):
- Действующее
- Исключен из ЕГРЮЛ на основании п.2 ст.21.1 №129-ФЗ (юрлицо в течении 12 мес. не представляло отчетности и не осуществляло операций по банковским счетам)
- Исключение из ЕГРЮЛ недействующего юридического лица
- Ликвидировано
- Ликвидировано вследствие банкротства
- Ликвидировано по решению суда
- Прекратило деятельность (Ликвидация юридического лица)
- Прекратило деятельность (Ликвидация некоммерческой организации по решению суда)
- Некоммерческая организация ликвидирована по решению суда
- Находится в стадии ликвидации
- Находится в процессе реорганизации в форме слияния
- Находится в процессе реорганизации в форме преобразования
- Юридическое лицо находится в процессе реорганизации в форме преобразования
- Находится в процессе реорганизации в форме присоединения (прекращает деятельность после реорганизации)
- Находится в процессе реорганизации в форме присоединения к нему других ЮЛ
- Юридическое лицо находится в процессе реорганизации в форме присоединения к нему других юридических лиц
- Находится в процессе реорганизации в форме присоединения к другому ЮЛ
- Юридическое лицо находится в процессе реорганизации в форме присоединения к другому юридическому лицу
- Юридическое лицо находится в процессе реорганизации в форме выделения
- Прекратило деятельность (Ликвидация юридического лица)
- Прекратило деятельность (Прекращение деятельности юридического лица путем реорганизации в форме преобразования)
- Прекратило деятельность (Прекращение деятельности юридического лица путем реорганизации в форме присоединения)
- Прекратило деятельность (Прекращение деятельности юридического лица в связи с его ликвидацией на основании определения арбитражного суда о завершении конкурсного производства)
- Прекратило деятельность (Прекращение деятельности юридического лица в связи с исключением из ЕГРЮЛ на основании п. 2 ст.21.1 Федерального закона от 08.08.2001 №129-ФЗ)
- Прекратило деятельность в связи с приобретением главы КФХ статуса ИП
- Прекратило деятельность при присоединении
- Прекратило деятельность при преобразовании
- Прекратило деятельность при слиянии
- Прекратило деятельность (Прекращение деятельности юридического лица путем реорганизации в форме слияния)
- Принято решение о предстоящем исключении недействующего ЮЛ из ЕГРЮЛ
- Регистрация признана недействительной по решению суда
- Регдело передано в другой регорган
- Исключение из ЕГРЮЛ юридического лица в связи наличием в ЕГРЮЛ сведений о нем, в отношении которых внесена запись о недостоверности
- Регистрирующим органом принято решение о предстоящем исключении юридического лица из ЕГРЮЛ (наличие в ЕГРЮЛ сведений о юридическом лице, в отношении которых внесена запись о недостоверности)
- Регистрирующим органом принято решение о предстоящем исключении юридического лица из ЕГРЮЛ (недействующее юридическое лицо)
 2 ст.21.1 Федерального закона от 08.08.2001 №129-ФЗ)
2 ст.21.1 Федерального закона от 08.08.2001 №129-ФЗ)История изменений
Все изменения в регистрационных данных (смена руководства, изменение юр. адреса, изменение состава или долей учредителей, изменение названия или организационно-правовой формы и др.) запоминаются и показываются в разделе “История”.
адреса, изменение состава или долей учредителей, изменение названия или организационно-правовой формы и др.) запоминаются и показываются в разделе “История”.
Порядок ведения реестра в ФНС
Ведение реестра юридических лиц регламентируется Федеральным законом от 08.08.2001 № 129-ФЗ “О государственной регистрации юридических лиц и индивидуальных предпринимателей” и поручено Федеральной налоговой службе. Работа с реестром ведется на нескольких “уровнях”:
Местный уровень – ответственной за ведение реестра является налоговая инспекция, именно в инспекцию руководители организаций подают соответствующие заявления о регистрации юр.лица, реорганизации, внесения изменений в уставные документы и т.п.
Региональный уровень – Управление ФНС, аккумулирует все данные из инспекций и передаёт их на федеральный уровень.
Федеральный уровень – ФНС Москва, ведет полный реестр всех юридических лиц России. Именно из реестра федерального уровня получает информацию сервис Контур. Фокус.
Фокус.
По нашему опыту работы с реестром, срок передачи данных с местного уровня на федеральный составляет от 1 до 4 недель.
Пересечение данных с Росстатом
Данные о предприятиях (состав учредителей и их доли) сервис Контур.Фокус получает также из Росстата. В том случае если эти данные расходятся с информацией из ФНС – отображаются и те и другие.
сведения Росстата
Приоритетом пользуются сведения из ФНС, т.к. изменения вносятся через несколько дней после подачи заявления о государственной регистрации изменений в учредительные документы (форма № Р13001) в налоговую инспекцию. А в Росстате сведения актуализируются раз в год – во время представления годовой бухгалтерской отчетности организациями.
Ограничения на предоставление информации
Доступ к перечисленной ниже информации НЕ может быть предоставлен:
- паспортные данные учредителей (участников)
- паспортные данные руководителя
- сведения о банковских счетах
Данную информацию может получить в налоговой инспекции только организация при оформлении запроса на саму себя. При этом запрос должен быть подписан руководителем организации, либо уполномоченным на то лицом, а так же заверен круглой печатью юридического лица (ст.6 Федерального закона 129-ФЗ “О государственной регистрации юридических лиц и индивидуальных предпринимателей”).
При этом запрос должен быть подписан руководителем организации, либо уполномоченным на то лицом, а так же заверен круглой печатью юридического лица (ст.6 Федерального закона 129-ФЗ “О государственной регистрации юридических лиц и индивидуальных предпринимателей”).
Выписка из ЕГРЮЛ в Контур.Фокус
Выписка из ЕГРЮЛ, предоставляемая сервисом Контур.Фокус, позволяет пользователю получить актуальную информацию о состоянии юридического лица, а также о видах осуществляемой деятельности.
Запрос выписки
Чтобы получить доступ к сведениям из ЕГРЮЛ по интересующей организации, нужно сформировать карточку компании и на вкладке «Сводка» будет представлен блок «Выписка из ЕГРЮЛ».
Блок “Выписка ЕГРЮЛ”
Далее нужно определить дату, на которую необходимо сформировать выписку. Стоит отметить, что системой Контур.Фокус сведения могут быть представлены за любые периоды начиная с 2016 года.
Формирование выписки на определённую дату
После выбора даты необходимо кликнуть «Сформировать», и пользователь получит выписку в формате . pdf, соответствующую выбранной дате.
pdf, соответствующую выбранной дате.
Сформированная выписка на 11.01.2016
Запрос выписки, заверенной ФНС
Если же нужно сформировать выписку в качестве официального документа, то на вкладке «Сводка» нужно найти блок «Выписка из ЕГРЮЛ», после необходимо кликнуть «Запросить с подписью ФНС».
Запрос выписки с подписью ФНС
Выписка сформируется по умолчанию на текущую дату и будет заверена усиленной квалифицированной электронной подписью ФНС.
Скачать выписку из ЕГРЮЛ с подписью ФНС (актуально на 25.09.2020).
- Выписка из ЕГРЮЛ лист 1-2
- Выписка из ЕГРЮЛ лист 3-4
- Выписка из ЕГРЮЛ лист 5-6
- Выписка из ЕГРЮЛ лист 7-8
- Выписка из ЕГРЮЛ лист 9-10
- Выписка из ЕГРЮЛ лист 11-12
- Выписка из ЕГРЮЛ лист 13-14
- Выписка из ЕГРЮЛ лист 15-16
- Выписка из ЕГРЮЛ лист 17-18
- Выписка из ЕГРЮЛ лист 19-20
- Выписка из ЕГРЮЛ лист 21-22
- Выписка из ЕГРЮЛ лист 23-24
- Выписка из ЕГРЮЛ лист 25-26
- Выписка из ЕГРЮЛ лист 27-28
- Выписка из ЕГРЮЛ лист 29
Планируемые изменения в ЕГРЮЛ
На вкладке «Сводка» можно также ознакомится с документами, поданными на регистрацию в ЕГРЮЛ. Подобные сведения позволят заранее узнать о планируемых изменениях касательно руководства, адреса, а также о возможной ликвидации.
Подобные сведения позволят заранее узнать о планируемых изменениях касательно руководства, адреса, а также о возможной ликвидации.
Такие сведения выделены отдельным блоком «Документы на изменения в ЕГРЮЛ».
Блок “Документы на внесение изменений в ЕГРЮЛ”
Чтобы более детально изучить документы нужно кликнуть «Подробнее». Перед пользователем появится информация в разрезе каждого обращения в налоговою инспекцию.
Карточки вносимых изменений
В каждой сформированной карточке указывается:
- дата заявления о внесении изменений в ЕГРЮЛ
- вид изменений, изменение состава учредителей, адреса и прочее
- входящий номер, присваивается в налоговой инспекции
- ИФНС, территориальный орган обращения
- форма заявления, указывается номер бланка, например, Р14001 или Р13001
- готовность документа, дата исполнения
- вид решения, вердикт налоговых органов, например, отказ или регистрация
Записи в ЕГРЮЛ
На вкладке «Сводка» отдельным блоком «Записи в ЕГРЮЛ» также представлены сведения об уже внесённых записях. Оранжевым цветом выделены записи, в отношении которых ФНС ещё не приняла решения (на это инспекции отводится 6 рабочих дней) либо был оформлен отказ.
Оранжевым цветом выделены записи, в отношении которых ФНС ещё не приняла решения (на это инспекции отводится 6 рабочих дней) либо был оформлен отказ.
Блок “Записи в ЕГРЮЛ”
Для просмотра записей нужно кликнуть «Подробнее». Перед пользователем появятся карточки, сформированные по каждой отдельной записи.
Карточки вносимых записей в ЕГРЮЛ
В зависимости от исхода решения инспекции, каждая карточка содержит свой набор сведений:
- дата записи
- содержание записи
- документы, которые сопровождали процесс создания записи в реестре
- регорган, указывается код и наименование территориального органа налоговой инспекции
- ГРН, прописывается государственный регистрационный номер, присвоенный записи
Выписка из ЕГРЮЛ может быть весьма полезной, с точки зрения оценки потенциального контрагента, поскольку она содержит в себе исчерпывающие сведения о руководителе, учредителях, регистрации в налоговых органах, отображаются сведения обо всех вносимых изменениях в учредительные документы. Также можно воспользоваться следующими возможностями системы Контур.Фокус: выписка ЕГРИП, налоги и сборы, сообщения эмитентов.
Также можно воспользоваться следующими возможностями системы Контур.Фокус: выписка ЕГРИП, налоги и сборы, сообщения эмитентов.
Источник информации
Информация о текущем состоянии выписки ЕГРЮЛ, а также обо всех вносимых изменениях, поступает на сервера системы Контур.Фокус из официального источника – базы данных Федеральной налоговой службы. Благодаря этому обеспечивается достоверность предоставляемых сведений.
Периодичность обновления
Веб-сервис Контур.Фокус ежедневно проводит сверку имеющейся информации с данными Федеральной налоговой службой. Это позволяет пользователю всегда располагать актуальной информацией об интересующей компании.
Доступно на тарифах
Премиум | Премиум+ | Бизнес |
Заявка на Контур.Фокус
Заполните все поля заявки, наши специалисты в самок ближайшее время свяжутся с Вами, проведут онлайн презентацию сервиса и помогут выбрать подходящий тариф:
Как извлечь часть строковой переменной с помощью регулярных выражений?
Обработка строк в Stata довольно проста из-за множества встроенных строковых
функции. Среди этих строковых функций есть три функции, связанные с
Среди этих строковых функций есть три функции, связанные с
регулярные выражения, regexm для сопоставления, regexr для замены и
регулярных выражения для подвыражений. Мы покажем несколько примеров использования
регулярное выражение для извлечения и/или замены части строковой переменной
используя эти три функции. Внизу страницы пояснение
все операторы регулярных выражений, а также функции, которые работают с
обычные выражения.
Примеры
Пример 1. Исследователь имеет адреса в виде строковой переменной и хочет создать новую переменную
который содержит только почтовые индексы.
Пример 2: У нас есть переменная, которая содержит полные имена в порядке первых
имя, а затем фамилию. Мы хотим создать новую переменную с полным именем в
порядок фамилии, а затем имени через запятую.
Пример 2: Даты вводились как строковая переменная, в некоторых случаях год вводился в виде четырехзначного числа
значение (это то, что Stata обычно ожидает увидеть), но в других случаях оно вводилось как двузначное
ценить. Мы хотим создать переменную даты в числовом формате на основе этой строки.
переменная. С этой задачей можно легко справиться с помощью обычных команд Stata, см. нашу страницу часто задаваемых вопросов.
«Моя переменная даты — это строка, как я могу превратить ее в переменную даты, которую Stata может
распознавать?» для получения информации о том, как это сделать. Мы включили этот пример
здесь для демонстрационных целей, а не потому, что регулярные выражения обязательно
лучший способ справиться с этой ситуацией.
В этих ситуациях можно использовать регулярные выражения для определения случаев, в которых
строка содержит набор значений (например, определенное слово, число, за которым следует слово
и т. д.) и извлечь этот набор значений из всей строки для использования в другом месте.
Пример 1. Извлечение почтовых индексов из адресов
Начнем с некоторых поддельных адресов.
адрес ввода str60 «4905 Лейкуэй Драйв, Колледж-Стейшн, Техас, 77845, США» "673 Жасмин Стрит, Лос-Анджелес, Калифорния" "2376 Первая улица, Сан-Диего, Калифорния
" "Уэст Сентрал Стрит, 6, Темпе, AZ 80068" «1234 Мэйн-Стрит-Кембридж, Массачусетс 01238-1234» конец
Чтобы найти почтовый индекс, мы будем искать пятизначное число в адресе.
Команда gen
(сокращение от «генерировать») ниже указывает Stata создать новую переменную с именем zip .
Остальная часть команды немного сложна, сначала оценивается «if», if(regexm(address, «[0-9][0-9][0-9][0-9][0-9]»))
ищет в переменной адрес пятизначное число и, если может
найти пятизначное число в переменной адрес , = regexs(0)
указывает, что Stata должна установить значение zip равным этому
пятизначное число. Мы указываем
что мы хотим пятизначное число, указав «[0-9]»
в пять раз. Если иное не указано с помощью *, + или ? знак, один и только один из
символы, содержащиеся в скобках, будут совпадать. Это означает, что нанизывание пяти из этих
выражения вместе позволят нам найти строку ровно из пяти цифр.
Обратите внимание, что 0-9указывает, что выражение должно соответствовать любому символу 0
до 9 (т. е. 0, 1, 2, 3, 4, 5, 6, 7, 8 и 9 совпадают).
gen zip = regexs(0) if(regexm(address, "[0-9][0-9][0-9][0-9][0-9]"))
список
+------------------------------------------------- -------------+
| почтовый индекс |
|------------------------------------------------- -------------|
1. | 4905 Lakeway Drive, Колледж-Стейшн, Техас 77845 США 77845 |
2. | 673 Jasmine Street, Лос-Анджелес, Калифорния
|
3. | 2376 Первая улица, Сан-Диего, Калифорния
|
4. | 6 West Central St, Tempe AZ 80068 80068 |
5. | 1234 Мейн-Стрит. Кембридж, Массачусетс 01238-1234 01238 |
+------------------------------------------------- -------------+ Пример 1, вариантный номер 1
В приведенном выше упрощенном примере ни один из адресов не содержит пятизначных номеров улиц.
числа. Что делать, если есть адреса с пятизначными номерами улиц? Давайте посмотрим
в другом наборе данных поддельных адресов и посмотреть, что происходит, когда мы пытаемся использовать
тот же код выше.
прозрачный введите адрес str60 «4905 Лейкуэй Драйв, Колледж-Стейшн, Техас 77845» «Жасмин-стрит, 673, Лос-Анджелес, Калифорния,». "2376 Первая улица, Сан-Диего, Калифорния
" "66666 West Central St, Tempe AZ 80068" «12345 Мэйн-Стрит-Кембридж, Массачусетс 01238» конец gen zip = regexs(0) if(regexm(адрес, "[0-9][0-9][0-9][0-9][0-9]")) список +------------------------------------------------- ---------+ | почтовый индекс | |------------------------------------------------- ---------| 1.
| 3. | 2376 Первая улица, Сан-Диего, Калифорния
| 4. | 66666 West Central St, Tempe AZ 80068 66666 | 5. | 12345 Мейн-Стрит. Кембридж, Массачусетс 01238 12345 | +------------------------------------------------- ---------+
Судя по всему, это работает некорректно, так как последние две строки
переменная zip подобрали номера улиц для этих адресов вместо почтовых индексов. В
этот набор данных, почтовый индекс появляется в конце адресной строки. Если мы
предположим, что это относится ко всем адресам в данных, исправление будет
очень просто. Мы можем указать «[0-9][0-9][0-9][0-9][0-9]$»
который проинструктирует Stata найти пятизначное число в конце строки.
gen zip = regexs(0) if(regexm(address, "[0-9][0-9][0-9][0-9][0-9]$"))
список
+------------------------------------------------- ---------+
| почтовый индекс |
|------------------------------------------------- ---------|
1. | 4905 Lakeway Drive, Колледж-Стейшн, Техас 77845 77845 |
2. | 673 Jasmine Street, Лос-Анджелес, Калифорния
|
3. | 2376 Первая улица, Сан-Диего, Калифорния
|
4. | 66666 West Central St, Tempe AZ 80068 80068 |
5. | 12345 Мейн-Стрит. Кембридж, Массачусетс 01238 01238 |
+------------------------------------------------- ---------+ Пример 1, номер варианта 2
Иногда почтовый индекс также включает четырехзначный добавочный номер и страну
имя может также появляться в конце адреса, например, в некоторых
адреса, указанные ниже.
прозрачный введите адрес str60 «4905 Лейкуэй Драйв, Колледж-Стейшн, Техас, 77845, США» «Жасмин-стрит, 673, Лос-Анджелес, Калифорния,». "2376 Первая улица, Сан-Диего, Калифорния
" "66666 West Central St, Tempe AZ 80068" «12345 Мэйн-Стрит-Кембридж, Массачусетс 01238-1234» "12345 Мэйн-Сент-Соммервиль, Массачусетс, Массачусетс 01239.-2345" "12345 Мейн-Стрит Уотертвон, Массачусетс, Массачусетс, 01239, США" конец
В этом типе более реалистичной ситуации код в предыдущем
примеры не будут работать правильно, так как после zip есть лишние символы
код, который необходимо извлечь. Вот как мы можем это сделать, используя более сложный регулярный
выражение.
gen zip = regexs(1) if regexm(address, "([0-9][0-9][0-9][0-9][0-9])[-]*[0-9 ]*[ a-zA-Z]*$")список+------------------------------------------------ --------------+ | почтовый индекс | |------------------------------------------------- -------------| 1. | 4905 Lakeway Drive, Колледж-Стейшн, Техас 77845 США 77845 | 2. | 673 Jasmine Street, Лос-Анджелес, Калифорния
| 3. | 2376 Первая улица, Сан-Диего, Калифорния
| 4. | 66666 West Central St, Tempe AZ 80068 80068 | 5. | 12345 Мейн-Стрит. Кембридж, Массачусетс 01238-1234 01238 | |------------------------------------------------- -------------| 6. | 12345 Мейн-Стрит Соммервиль MA 01239-2345 01239 | 7. | 12345 Main St Watertwon MA 01239 США 01239 | +------------------------------------------------- -------------+
Мы добавили в регулярное выражение следующее: «[-]*[0-9]*[ a-zA-Z]*» .
В этом регулярном выражении есть три компонента.
- [-]* – совпадение нуля или более дефисов «-»
- [0-9]* – совпадение нуля или более чисел
- [a-zA-Z]* — совпадение нуля или более пробелов или букв
Эти дополнения позволяют нам сопоставлять случаи, когда есть замыкающие
символов после почтового индекса и для правильного извлечения почтового индекса. Заметить, что
мы также использовали «регулярные выражения (1)» вместо «регулярных выражений (0)», как мы делали ранее, потому что мы
теперь используют подвыражения, указанные парой скобок в « ([0-9][0-9][0-9][0-9][0-9]) «.
Другая стратегия, которая может работать лучше в некоторых случаях, — это регулярное выражение
.
gen zip2 = regexs(1) if(regexm(address, ".*([0-9][0-9][0-9][0-9][0-9])"))
В этом примере точка (т. е. «.») соответствует любому символу, а одна звездочка («*») соответствует любому
персонажи. Вместе, два
указать, что искомое число не должно встречаться в самом
начало строки, но может появиться в любом месте после.
Пример 2: Извлечение имени и фамилии и переключение их порядка
У нас есть переменная, которая содержит полное имя человека в порядке имени и
затем фамилия. Мы хотим создать новую переменную для полного имени в порядке
фамилия, а затем имя через запятую. Для начала давайте сделаем образец данных
набор.
прозрачный введите str40 полное имя "Джон Адамс" "Адам Смитс" "Мэри Смитс" "Чарли Уэйд" конец
Теперь нам нужно захватить первое слово и второе слово и поменять их местами. Здесь
регулярное выражение для этой цели: (([a-zA-Z]+)[ ]*([a-zA-Z]+)).
Это регулярное выражение состоит из трех частей:
- ([a-zA-Z]+) — подвыражение , захватывающее строку, состоящую из
буквы, как строчные, так и прописные. Это будет первое имя. - [ ]* – совпадение с пробелами. Это расстояние между первым
имя и фамилия. - ([a-zA-Z]+) – подвыражение, захватывающее строку, состоящую из
буквы. Это будет фамилия.
gen n = regexs(2)+", "+regexs(1) if regexm(fullname, "([a-zA-Z]+)[ ]*([a-zA-Z]+)")
список
+-------------------------------+
| полное имя п |
|-------------------------------|
1. | Джон Адамс Адамс, Джон |
2. | Адам Смитс Смитс, Адам |
3. | Мэри Смитс Смитс, Мэри |
4. | Чарли Уэйд Уэйд, Чарли |
+---------------------------------------------+ Это действительно работает. Давайте посмотрим, как регулярных выражений работают в этом случае. регулярное выражение
фактически идентифицирует ряд разделов на основе всего выражения, а также
подвыражения. Следующий код использует регулярных выражения для размещения каждого из этих
компоненты (подвыражения) в свою собственную переменную
а затем отображает их.
gen n0 = regexs(0) if regexm(fullname, "(([a-zA-Z]+)[ ]*([a-zA-Z]+))")
gen n1 = regexs(2) if regexm(полное имя, "(([a-zA-Z]+)[ ]*([a-zA-Z]+))")
gen n2 = regexs(3) if regexm(полное имя, "(([a-zA-Z]+)[ ]*([a-zA-Z]+))")
список полных имен n0 n1 n2
+------------------------------------------------+
| полное имя n0 n1 n2 |
|------------------------------------------------|
1. | Джон Адамс Джон Адамс Джон Адамс |
2. | Адам Смитс Адам Смитс Адам Смитс |
3. | Мэри Смитс Мэри Смитс Мэри Смитс |
4. | Чарли Уэйд Чарли Уэйд Чарли Уэйд |
+------------------------------------------------+ Пример 3: Двух- и четырехзначные значения года.
В этом примере у нас есть даты, введенные как строковая переменная. Стата может справиться
это с помощью стандартных команд (см. «Моя переменная даты является строкой, как я могу
превратить его в переменную даты, которую Stata может распознать?»), мы используем это как пример того, что
вы могли бы сделать с регулярными выражениями. Целью этого процесса является создание строки
переменная с соответствующим четырехзначным годом для каждого случая, который Stata может
затем легко преобразовать в дату. Для этого начнем с разделения
вывести каждый элемент даты (день, месяц и год из двух или четырех цифр) в
отдельная переменная, то мы будем присваивать случаям правильный четырехзначный год
где в настоящее время только две цифры, наконец, мы объединяем переменные, чтобы создать одну
строковая переменная, которая содержит месяц, день и год из четырех цифр.
Сначала введите даты:
ввод даты str18 20 января 2007 г. 16 июня 2006 г. 06 сентября 1985 г. 21 июня 2004 г. 4июля90 9 января 1999 г. 6 августа 99 г. 19 августа 2003 г. конец
Далее мы хотим определить день месяца и поместить его в переменную
позвонил день . Для этого мы проинструктируем Stata найти день, глядя на
начало строки (т.е. дата),
для одного или нескольких значений от 0 до 9. (Другими словами, ищите номер
в начале строки, так как мы знаем, что первая серия чисел
день.) Создать новую переменную 9[0-9]+»)
Строка синтаксиса ниже находит месяц, ища одну или несколько букв вместе в строке.
Затем генерирует переменную month и устанавливает ее равной месяцу, указанному в строке.
gen month = regexs(0) if regexm(date, "[a-zA-Z]+")
В этом году все становится сложнее. Обратите внимание, что значения для присвоения
столетия основаны на моем знании моих «данных». Прежде всего, мы извлекаем все
цифры для года. Мы используем оператор «$», чтобы указать, что поиск ведется из
конец строки. Затем мы превращаем строковую переменную в числовую переменную
используя функцию Stata «real». Следующее действие включает в себя работу с двузначными годами
начиная с «0». Это соответствует последним годам двадцать первого века.
Чтобы превратить их в четырехзначные годы, мы объединяем (используя +) строку
идентифицируется (год из двух цифр) строкой «20». Далее мы найдем
двузначные годы 10-9[1-9][0-9]$»)
gen date2 = день+месяц+год
список
+————————————————- —+
| дата день месяц год date2 |
|————————————————- —|
1. | 20 января 2007 г. 20 января 2007 г. 20 января 2007 г. |
2. | 16 июня 2006 г. 16 июня 2006 г. 16 июня 2006 г. |
3. | 06 сентября 1985 г. 06 сентября 1985 г. 06 сентября 1985 г. |
4. | 21 июня 2004 г. 21 июня 2004 г. 21 июня 2004 г. |
5. | 4июля90 4 июля 1990 г. 4 июля 1990 г. |
|————————————————- —|
6. | 9 января 1999 г. 9 января 1999 г. 9 января 1999 г. |
7. | 6 августа 1999 г. 6 августа 1999 г. 6 августа 1999 г. |
8. | 19 августа 2003 г. 19 августа 2003 г. 19 августа 2003 г. |
+————————————————- —+
Регулярные выражения
Регулярные выражения, как правило, являются способом поиска и в некоторых случаях замены
появление шаблона в строке на основе набора правил. Эти правила
определяется набором операторов. Следующее
Таблица показывает все операторы, которые принимает Stata, и поясняет каждый из них. Обратите внимание, что
в Стате,
регулярные выражения всегда заключаются в кавычки.
[ ] Квадратные скобки означают, что один из символов внутри
скобки должны совпадать. Например, если я хочу найти
одна буква между f и m, я бы набрал «[f-m]»а-я Диапазон указывает, что допустимо любое значение в этом диапазоне.
Это чувствительно к регистру, поэтому az не совпадает с AZ, если любой регистр
может считаться совпадением, включая оба a-zA-Z. Числовые значения также
приемлемо в виде диапазонов (например, 0-9).. Точка соответствует любому символу. Позволяет сопоставлять символы, которые обычно являются регулярными выражениями
операторы. Например, если вы хотите сопоставить «[«, введите [ вместо
всего один [.* Совпадает с нулем или более символов в предыдущем выражении. Например
если бы я хотел сопоставить число, состоящее из одной или нескольких цифр, если есть
число, но все же
хотите указать совпадение, если остальная часть выражения подходит, я мог бы указать
[0-9″ указывает
что следующее выражение должно появиться в начале строки.$ Если в конце выражения появляется символ «$», это означает, что
предыдущее выражение должно стоять в конце строки.
если бы я хотел сопоставить число, которое появилось последним
в конце строки я бы указал «[0-9]+$»| Логический оператор или, указывающий, что либо выражение
предшествующий
это или следующее за ним квалифицируется как совпадение.( ) Создает подвыражение внутри большего выражения. Полезно с
оператор «или» (т.е. | ), и
при извлечении и замене значений. Например, если я хочу извлечь числовое
значение, которое, как я знаю, следует сразу после слова или набора букв, я мог бы использовать
регулярное выражение «[a-zA-Z]+([0-9]+)» соответствует всему
выражение, но позволяет выбрать часть в скобках
(называется подстрокой). Обработка подстрок обсуждается в
более подробно ниже.Эти выражения можно комбинировать для поиска самых разных строк.
Как упоминалось выше, есть три типа функций, которые могут быть предварительно сформированы.
с регулярными выражениями в Stata (если вы творческий человек, вы можете сделать любое количество
другие вещи, использующие эти функции, но основными инструментами являются встроенные функции Stata).
отдельные команды для каждого из трех типов действий регулярных выражений могут
выполнить:
- регулярное выражение — используется для поиска совпадающих строк, оценивается как единица, если есть совпадение,
и ноль иначе- регулярных выражений — используется для возврата n -й подстроки в выражении
соответствует регулярному выражению (следовательно, регулярное выражение всегда должно запускаться перед регулярными выражениями, обратите внимание
что «если» оценивается первым, даже если оно появляется позже в строке
синтаксис).- regexr — используется для замены совпадающего выражения чем-то другим.
Каждый из них имеет немного отличающийся синтаксис. Строка ниже показывает синтаксис для
regexm , то есть функция, соответствующая вашему регулярному выражению, где
строка может быть строкой, которую вы вводите сами, строкой из макроса или
обычно имя переменной. Регулярное выражение является регулярным
выражение для строки, которую вы хотите найти, обратите внимание, что оно должно появиться в
кавычки.регулярное выражение ( строка , " регулярное выражение ")Для регулярных выражений, то есть для вызова всей строки или ее части, используется следующий синтаксис:
регулярных выражений ( н )Где n — это номер, присвоенный подстроке, которую вы хотите извлечь.
Подстроки фактически разделяются при запуске регулярного выражения. Вся подстрока
возвращается нулем, и каждая подстрока последовательно нумеруется от 1 до n. Для
например, регулярное выражение(«907-789-3939», «([0-9]*)-([0-9]*)-([0-9]*)») возвращает следующее:
Подвыражение # Возвращенная строка 0 907-789-3939 1 907 2 789 3 3939 Обратите внимание, что в подвыражениях 1, 2 и 3 пропущены тире, так как они
не заключаются в круглые скобки, которые отмечают подвыражения.Вы можете еще раз взглянуть на то, как это работает, используя следующий синтаксис, который
использует команду display для запуска функции.отображать регулярное выражение("907-789-3939", "([0-9]*)-([0-9]*)-([0-9]*)") отображать регулярные выражения (0) отображать регулярные выражения (1) отображать регулярные выражения (2) отображать регулярные выражения (3)Поскольку это функции, команды регулярных выражений работают внутри других команд (например, генерировать),
но не могут быть использованы сами по себе (т.е. вы не можете запустить команду в Stata с
регулярное выражение(…)).
Артикул
Регулярные выражения: Использование модуля «re» для извлечения информации из строк | Мюриэль Косака
Различия между функциями findall(), match() и search() во встроенном модуле регулярных выражений Python.
Photo by Abigail Lynn on Unsplash
Регулярные выражения, также известные как Regex, пригодятся во множестве сценариев обработки текста. Вы можете искать шаблоны цифр, букв, знаков препинания и даже пробелов. Regex работает быстро и помогает избежать ненужных циклов в вашей программе для сопоставления и извлечения нужной информации. До недавнего времени я чувствовал, что Regex очень сложен, синтаксис выглядит разочаровывающим, и думал, что не смогу о нем узнать. Как и многие другие, мы разделяем это чувство.
imgflip.com
Прочитав много ресурсов в Интернете, я решил использовать этот пост, чтобы показать, как вы можете использовать модуль «re» в Python для решения определенных проблем с помощью функции findall() и кратко представить match(), и функции поиска(); все они похожи, но имеют разное применение.
Использование регулярных выражений в Python
Чтобы начать использовать Regex в Python, сначала необходимо импортировать модуль «re» Python
import re
Этот пост разделен на три раздела, в которых рассматриваются три простые функции для извлечения полезной информации из строк. с примерами.
- findall()
- match()
- search()
re.findall(): Поиск всех совпадений в строке/списке строк, содержащих все совпадения. Если шаблон не найден,
re.findall() возвращает пустой список. Давайте посмотрим, когда мы сможем использовать функцию findall() !
- Извлечь все вхождения определенных слов
Используя следующий текстовый абзац, в котором описывается, как Рей, африканский пингвин, и Роза, самая старая морская выдра в Аквариуме залива Монтерей, нуждаются в глазных каплях.
аквариум='Из-за проблем со зрением у африканского пингвина Рей были проблемы с плаванием. Это необычно для пингвина, и нашей команде по птицеводству было сложно помочь Рей преодолеть ее нерешительность. Медленно и неуклонно мы приучали ее к кормлению в воде, как и к остальной колонии пингвинов. Птицеводы также научили Рей принимать от них ежедневные глазные капли в рамках ее особого ухода за здоровьем.
Теперь вы хотите извлечь все вхождения Рей из текста, для чего вы должны сделать что-то вроде этого:
rey_occurences = "Рей"
re.findall(rey_occurences, аквариум)# Вывод
['Рей', ' Rey', 'Rey', 'Rey']
Функция findall() принимает два параметра, первый — это искомый шаблон, в нашем случае rey_occurrences , а второй параметр — это текст, который мы ищем, в нашем случае аквариум . Как видите, эта функция возвращает все непересекающиеся совпадения шаблона, который находится в rey_occurrences переменных, из второго параметра аквариум .
Но подождите, есть еще один Рей, который не был учтен. Это произошло потому, что по умолчанию регулярные выражения чувствительны к регистру, поэтому наша функция findall() не вернула «rey», потому что это строчные, а не прописные буквы, как было определено в переменных rey_occurrences . Мы можем отредактировать наш предыдущий код, чтобы он включал значения искомого шаблона в нижнем регистре, включив третий параметр, флаги , которые можно использовать по разным причинам, например, чтобы шаблоны соответствовали определенным строкам, а не всему тексту, сопоставляли шаблоны, охватывающие несколько строк, и выполняли сопоставление без учета регистра. Для наших целей мы будем использовать флаг re.IGNORECASE , чтобы игнорировать регистр при выполнении поиска.
rey_occurences = "Rey"
re.findall(rey_occurences,aquarium,flags=re.IGNORECASE)# Вывод
['rey', 'Rey', 'Rey', 'Rey', 'Rey']
Мы можем также искать несколько шаблонов и извлекать все вхождения этих шаблонов. С нашим текущим текстом давайте также найдем вхождения «Розы», просто используя | Оператор для создания шаблона.
sea_animals="Рей|Роза"
re.findall(sea_animals,aquarium,flags=re.IGNORECASE)# Вывод
['rey', 'Rey', 'Rey', 'Rey', 'Rey', 'Rosa ', 'Роза']
| оператор — это специальный символ, который указывает Regex искать шаблон один или шаблон два в тексте. Если вы хотите найти вхождение «|» в вашем тексте вам нужно будет добавить его в свой шаблон с обратной косой чертой, «\| ». Эта обратная косая черта указывает Regex прочитать символ | оператор как символ без вывода его специального значения.
2. Извлечение слов, содержащих только буквы алфавита
Допустим, у вас есть текстовый документ, содержащий числа и слова, например:
подарки = "\
Баскетбол 2 25,63\
Футболка 4 53,92\
Кроссовки 1\
Mask 10 80.
GiftCard 2 50.00"
Допустим, вы хотите извлечь только слова; мы можем сделать это, используя специальные последовательности и наборы Regex, чтобы указать шаблон, который мы ищем. Этот полезный сайт предоставляет хорошую шпаргалку по Regex.
words = '[az]+'
re.findall(words,gifts,flags=re.IGNORECASE)# Вывод
['Баскетбол', 'Футболка', 'Кроссовки', 'Маска', 'Подарочная карта']
При установке нашего шаблона на [az] это означает класс символов от «a» до «z», в то время как оператор + соответствует одному или нескольким повторениям предыдущего регулярного выражения или класса, который в нашем случае [az] . Обратите внимание, что шаблон [az] по-прежнему возвращает прописные буквы, это из-за нашего флага re.IGNORECASE .
3. Извлечение всех вхождений чисел
Мы показали только извлечение слов из текста, можем ли мы также извлекать числа? Конечно, используя регулярные выражения из другой полезной шпаргалки, мы можем извлечь числа из заданного текста:
text = "Шестьдесят шесть студентов бакалавриата городского колледжа в Нью-Йорке приняли участие в этом исследовании.
re.findall(numbers,text)# Результат
['36','18','52','20','52','6','97','10','18','28','23','5',' 12','36']
Установив наш шаблон в \d, это означает одну цифру, в то время как оператор + будет включать повторы цифр. Как вы можете видеть из нашего текста, у нас также есть десятичные дроби, но из нашего вывода они были разделены знаком «.» Мы можем исправить это, используя следующее регулярное выражение:
all_numbers="\d+\.
re.findall(all_numbers,text)# Вывод
['36', '18', '52', '20.52', '6.97', '10' , '18', '28', '23.5', '12.36']
Как мы видели ранее, наличие шаблона \d+ будет захватывать одну цифру, за которой следуют повторы цифр, чтобы включить десятичные дроби, мы используем шаблон .*? будет искать совпадение, используя как можно меньше символов.
4. Извлечение слов, за которыми следует определенный шаблон
При работе с текстовыми данными могут возникнуть ситуации, когда вам потребуется извлечь слова, за которыми следует специальный символ, например @ для имен пользователей или кавычек в данном тексте.
В нашем тексте аквариум есть две цитаты, давайте извлечем их из текста.
quotes='"(.*?)"'
re.findall(quotes,aquarium)# Output
['Она знает распорядок,',
'Обычно я даю ей глазные капли в одном месте выставки после все пингвины получают свои витамины. Когда это происходит, она бежит туда и ждет меня.
Мы устанавливаем наш шаблон на «(.+?)»‘, где одинарные кавычки представляют тело текста, а двойные кавычки представляют кавычки внутри текст. У нас есть скобка, которая создает группу захвата и .*? является нежадным модератором и извлекает только кавычки, а не текст между кавычками.
Как видите, функция findall() модуля Python Regex может быть очень полезна при поиске списка со всеми необходимыми совпадениями. Эту функцию иногда путают с функциями match() и search() одного и того же модуля. Кратко обсудим разницу.
re.match(): возвращает первое вхождение в тексте
В то время как re.findall() возвращает совпадения подстроки, найденной в тексте, re.match() ищет только с начала строки и возвращает объект соответствия, если он найден. Однако, если совпадение найдено где-то в середине строки, ничего не возвращается.
Выражение «w+» и «\W» будет соответствовать словам, начинающимся с буквы «r», и после этого все, что не начинается с «r», не идентифицируется. Чтобы проверить совпадение для каждого элемента в списке или строке, мы запускаем цикл for в этом примере Python re.match() :
list = ["красная роза", "красный рубин", "розовый пион"]# Цикл.
для элемента в списке:
m = re.match("(r\w+)\W(r\w+)", element)if m:
print(m.groups())# Вывод
("красный", 'rose')
('ruby', 'red')
re.search(): Поиск шаблона в тексте
Функция re.search() будет искать шаблон регулярного выражения и возвращать первое вхождение. В отличие от Python re.match(), он проверяет все строки входной строки. Если шаблон найден, будет возвращен соответствующий объект, в противном случае возвращается «null».
Patterns=['penguin','Rosa']aquarium_short="Из-за проблем со зрением у африканского пингвина Рей были проблемы с плаванием."for Pattern in Patterns:
print('Ищем "%s" в "%s" = '% (шаблон, аквариум_шорт), конец=" ")if re.search(шаблон, аквариум_шорт):
print("Соответствие найдено")
else:
print("Соответствие не найдено")# Результат
Поиск "пингвина" в "Из-за проблем со зрением у африканского пингвина Рей были проблемы с плаванием.
В этом примере мы искали две строки «пингвин» и «Роза» в текстовой строке «Из-за проблем со зрением у африканского пингвина Рей были проблемы с плаванием». Для «пингвина» мы нашли совпадение, поэтому он возвращает вывод «Совпадение найдено», а слово «Роза» не найдено в строке и возвращает «Совпадение не найдено».
В то время как re.search() ищет первое вхождение совпадения в строке, re.findall() ищет все вхождения совпадения, а re.search() совпадений в начало строки, а не в начале каждой строки. Дополнительные операции, которые можно использовать с модулем Python Regex, см. в документации.
re — Операции с регулярными выражениями — Документация по Python 3.9.1
Этот модуль обеспечивает операции сопоставления с регулярными выражениями, подобные тем, что используются в Perl.
И узоры, и струны…
docs.python.org
Надеюсь, это было полезно! Спасибо за чтение! 🙂
Надежные решения для проверки личности и криминалистические устройства от Regula
Что такое файлы cookie?
Cookies — небольшие текстовые файлы, которые сохраняются веб-браузером (например, Internet Explorer, Firefox, Chrome и др.) в настройках пользователя (на компьютере, смартфоне, планшете), когда пользователь посещает веб-сайт. Это позволяет идентифицировать браузер или сохранять информацию и настройки в браузере. Таким образом, использование файлов cookie позволяет веб-сайту сохранять индивидуальные настройки пользователя, распознавать пользователя и соответствующим образом реагировать с целью улучшения опыта использования веб-сайта. Обычно файлы cookie не содержат никакой информации, которая могла бы идентифицировать пользователя, но ваша личная информация может быть связана с информацией, полученной или сохраненной с помощью файлов cookie. Пользователь может отказаться от использования или ограничить использование файлов cookie, однако отказ от использования файлов cookie не позволяет пользователю в полной мере использовать все функциональные возможности веб-сайта. Файлы cookie различаются в зависимости от их функций и целей их использования. На сайтах компании Регула используются обязательные, функциональные, аналитические и целевые (рекламные) файлы cookie.
Обязательные или «необходимые» файлы cookie
Эти файлы cookie необходимы для того, чтобы пользователь мог свободно посещать и просматривать веб-сайт, а также использовать возможности, предлагаемые веб-сайтом, а именно, получать информацию о продуктах, предоставляемых Regula. Эти файлы cookie идентифицируют устройство пользователя, сохраняя при этом анонимность пользователя. Эти файлы cookie не собирают и не обрабатывают информацию. Без использования этих файлов cookie веб-сайт не может в полном объеме выполнять свои функции, например, предоставлять пользователю необходимую информацию, обеспечивать выполнение услуг, запрошенных в интернет-магазине, подключение к профилю или обработку заказов. Эти файлы cookie хранятся на устройстве пользователя до момента закрытия браузера.
Функциональные или предпочтительные файлы cookie
Благодаря функциональным файлам cookie веб-сайт запоминает настройки, выбранные пользователем, и его предпочтения, например, выбранный регион и страну, что повышает удобство использования веб-сайта. Эти файлы cookie постоянно хранятся на устройстве пользователя.
Статистические файлы cookie
Статистические файлы cookie обобщают информацию о привычках использования веб-сайта, наиболее часто посещаемых разделах, предпочтительном контенте, который пользователь выбирает при посещении веб-сайта. Полученная информация анализируется с целью определения интересов пользователя, а также с целью повышения функциональности и удобства использования сайта. Статистические файлы cookie идентифицируют только устройство пользователя, сохраняя анонимность пользователя. В некоторых случаях вместо владельца веб-сайта некоторые аналитические файлы cookie управляются третьей стороной — оператором обработки данных, например Google Adwords, по поручению владельца веб-сайта и только для достижения целей, определенных владельцем.
Целевые или маркетинговые файлы cookie
Целевые (рекламные) файлы cookie используются для обобщения информации о веб-сайтах, посещаемых пользователями. Это позволяет предлагать услуги, предлагаемые нашей компанией или нашими партнерами, в которых заинтересован конкретный пользователь, соответствующему пользователю, а также направлять предложения, соответствующие интересам конкретных пользователей, соответствующим пользователям. Обычно эти файлы cookie размещаются третьими лицами, например, Google Adwords, с разрешения владельца веб-сайта и в соответствии с указанными целями. Целевые файлы cookie обычно постоянно хранятся на устройстве пользователя.
Google Analytics
Программное обеспечение Google Analytics используется для обеспечения функциональности веб-сайта Regula. Информация о вашем веб-сайте с использованием привычек, полученная с помощью этих файлов cookie, отправляется на серверы Google за границей и, следовательно, может храниться за пределами Латвии или Европейского Союза. Эта информация может храниться, например, на территории США.
В соответствии с Условиями предоставления услуг Google Inc. и Условиями предоставления услуг Google Analytics, Google будет использовать эту информацию для оценки использования веб-сайта и для составления отчетов об активности посетителей Regula сайты. Вы можете отказаться от использования файлов cookie Google Analytics, загрузив и установив подключаемый модуль Google Analytics Opt-out Browser Add-on.
Для получения более подробной информации об инструментах Google Analytics, работе, а также обеспечении защиты и конфиденциальности данных перейдите по этой ссылке.
Zendesk Support
Regula использует интегрированную систему поддержки клиентов Zendesk для отслеживания, приоритизации и реализации заявок, полученных службой поддержки клиентов. Это позволяет сконцентрировать все операции поддержки в одном центре, в результате чего общение с клиентами становится беспрепятственным, персонализированным и эффективным.
Чтобы узнать больше об инструментах, операциях, а также о защите данных и конфиденциальности Zendesk, перейдите по этой ссылке. Чтобы ознакомиться с условиями обработки файлов cookie Zendesk, нажмите здесь.
В каких целях (задачах) Regula использует файлы cookie Для
Regula использует файлы cookie для улучшения опыта использования наших веб-сайтов и порталов, а именно:
- Для обеспечения функциональности и управления веб-сайтом;
- Для адаптации функциональности веб-сайта в соответствии с привычками пользователя, например, в отношении языка использования;
- Для сбора статистики использования сайта собираются стандартные записи журнала: количество посетителей, продолжительность посещения, время подключения, IP-адрес, модель и тип устройств и другая анонимная информация о ваших действиях на сайте;
- «запоминать» о данном согласии посетителя сайта на обработку необязательных файлов cookie;
- В случае использования технических услуг файлы cookie используются для обеспечения защищенного соединения с клиентом;
Информация, хранящаяся в файле cookie, не используется для идентификации вас как физического лица.
Как долго хранятся файлы cookie?
Если не указано иное, файлы cookie сохраняются до тех пор, пока они не реализуют назначенные функции. После выполнения соответствующей функции файлы cookie удаляются. Подробнее см. в таблицах 1 — 4.
Согласие или отказ от использования файлов cookie
При входе на наш веб-сайт отображается уведомление с информацией о том, что веб-сайт использует файлы cookie. Вы можете дать свое согласие или отозвать свое согласие на использование файлов cookie определенной группы, поставив или убрав знак «Ö» рядом с файлами cookie соответствующей группы. Вы можете изменить сделанный вами выбор в любое время — в нижней части главной страницы есть ссылка «Настройки файлов cookie». Нажимая «Сохранить изменения», вы подтверждаете, что ознакомились с Условиями использования файлов cookie, включая информацию о файлах cookie и целях их использования, а также подтверждаете выбранные параметры в отношении конкретных типов файлов cookie. Настройки безопасности любого интернет-браузера позволяют ограничить использование файлов cookie или отключить файлы cookie. Тем не менее, имейте в виду, что полная функциональность работы веб-сайта будет невозможна, если вы решите отключить обязательные файлы cookie.
Контактная информация
Чтобы узнать больше о нас и о том, как мы обрабатываем ваши личные данные, ознакомьтесь с нашей Политикой конфиденциальности или свяжитесь с нами по электронной почте [email protected].
Cookies www.regulaforensics.com
| Category | Name | Provider | Purpose | Validity | Type | |||
|---|---|---|---|---|---|---|---|---|
| Necessary | test_cookie | doubleclick.net | Used to check если браузер пользователя поддерживает файлы cookie. | 1 день | HTTP | |||
| bscookie | linkedin.com | Этот файл cookie используется для идентификации посетителя через приложение. Это позволяет посетителю войти на веб-сайт, например, через приложение LinkedIn. | 1 год | HTTP | ||||
| li_gc | linkedin.com | Сохраняет состояние согласия пользователя на использование файлов cookie для текущего домена | 179 дней | 0226 CookieConsent | regulaforensics.com | Этот файл cookie используется для определения того, принял ли посетитель окно согласия на использование файлов cookie. | Сеанс | HTTP |
| XSRF-TOKEN | regulaforensics.com | Обеспечивает безопасность просмотра посетителем, предотвращая подделку межсайтовых запросов. Этот файл cookie необходим для безопасности веб-сайта и посетителей. | 1 день | HTTP | ||||
| Настройки | lang | ads.linkedin.com | Запоминает языковую версию веб-сайта, выбранную пользователем | Сеанс | HTTP | |||
| lidc | linkedin.com | Регистрирует, какой кластер серверов обслуживает посетителя. Это используется в контексте балансировки нагрузки, чтобы оптимизировать взаимодействие с пользователем. | 1 день | HTTP | ||||
| intercom.intercom-state-# | regulaforensics.com | Запоминает, сворачивал ли пользователь или закрывал окно чата или всплывающие окна на сайте. | Постоянный | HTML | ||||
| intercom-id-# | regulaforensics.com | Позволяет веб-сайту узнавать посетителя для оптимизации функциональности чата. | 270 дней | HTTP | ||||
| intercom-session-# | regulaforensics.com | Устанавливает определенный идентификатор для пользователя, который обеспечивает целостность функции чата на веб-сайте. | 6 дней | HTTP | ||||
| Статистика | c.gif | c.clarity.ms | Собирает данные о навигации и поведении пользователя на веб-сайте. Это используется для составления статистических отчетов и тепловых карт для владельца сайта. | Сеанс | Пиксел | |||
| CLID | clear.ms | Собирает данные о навигации и поведении пользователя на веб-сайте. Это используется для составления статистических отчетов и тепловых карт для владельца сайта. | 1 год | HTTP | ||||
| collect | google-analytics.com | Используется для отправки данных в Google Analytics об устройстве и поведении посетителя. Отслеживает посетителей по устройствам и маркетинговым каналам. | Сеанс | Пиксель | ||||
| AnalyticsSyncHistory | linkedin.com | Используется в связи с синхронизацией данных со сторонней аналитической службой. | 29 дней | HTTP | ||||
| __utmz | regulaforensics.com | Собирает данные о том, откуда пришел пользователь, какая поисковая система использовалась, какая ссылка была нажата и какой поисковый запрос был использован. Используется Google Analytics. | Сеанс | HTTP | ||||
| _clck | regulaforensics.com | Собирает данные о навигации и поведении пользователя на веб-сайте. Это используется для составления статистических отчетов и тепловых карт для владельца сайта. | 1 год | HTTP | ||||
| _clsk | regulaforensics.com | Регистрирует статистические данные о поведении пользователей на сайте. Используется для внутренней аналитики оператором сайта. | 1 день | HTTP | ||||
| _cltk | regulaforensics.com | Регистрирует статистические данные о поведении пользователей на сайте. Используется для внутренней аналитики оператором сайта. | Сеанс | HTML | ||||
| _ga | regulaforensics.com | Регистрирует уникальный идентификатор, который используется для создания статистических данных о том, как посетитель использует веб-сайт. | 399 дней | HTTP | ||||
| _ga_# | regulaforensics. com | Используется Google Analytics для сбора данных о том, сколько раз пользователь посещал веб-сайт, а также о датах первого и последнего посещения. | 399 days | HTTP | ||||
| _gat | regulaforensics.com | Used by Google Analytics to throttle request rate | 1 day | HTTP | ||||
| _gid | regulaforensics.com | Registers a unique ID который используется для создания статистических данных о том, как посетитель использует веб-сайт. | 1 день | HTTP | ||||
| ln_or | regulaforensics.com | Регистрирует статистические данные о поведении пользователей на сайте. Используется для внутренней аналитики оператором сайта. | 1 день | HTTP | ||||
| https://#.#/ | tr.lfeeder.com | Регистрирует статистические данные о поведении пользователей на сайте. Используется для внутренней аналитики оператором сайта. | Session | Pixel | ||||
| Marketing | SRM_B | bing.com | Отслеживает взаимодействие пользователя с функцией поиска веб-сайта. Эти данные могут быть использованы для предоставления пользователю соответствующих продуктов или услуг. | 1 год | HTTP | |||
| ANONCHK | c.clarity.ms | Регистрирует данные о посетителях из нескольких посещений и на нескольких веб-сайтах. Эта информация используется для измерения эффективности рекламы на веб-сайтах. | 1 день | HTTP | ||||
| SM | c.clarity.ms | Регистрирует уникальный идентификатор, который идентифицирует устройство пользователя во время повторных посещений веб-сайтов, использующих ту же рекламную сеть. Идентификатор используется для разрешения целевой рекламы. | Сеанс | HTTP | ||||
| MUID | clear.ms | Широко используется корпорацией Майкрософт в качестве уникального идентификатора пользователя. Файл cookie позволяет отслеживать пользователей, синхронизируя идентификатор во многих доменах Microsoft. | 1 год | HTTP | ||||
| pagead/landing | doubleclick.net | Собирает данные о поведении посетителей с нескольких веб-сайтов, чтобы показывать более релевантную рекламу. им показывают одну и ту же рекламу. | Сеанс | Пиксель | ||||
| ads/ga-audiences | google.com | Используется Google AdWords для повторного привлечения посетителей, которые могут превратиться в клиентов на основе поведения посетителя на веб-сайтах. | Session | Pixel | ||||
| pagead/landing | google.com | Собирает данные о поведении посетителей с нескольких веб-сайтов, чтобы показывать более релевантную рекламу. показывают одну и ту же рекламу. | Session | Pixel | ||||
| bcookie | linkedin.com | Используется социальной сетью LinkedIn для отслеживания использования встроенных сервисов. | 1 год | HTTP | ||||
| UserMatchHistory | linkedin.com | Обеспечивает безопасность навигации посетителей, предотвращая подделку межсайтовых запросов. Этот файл cookie необходим для безопасности веб-сайта и посетителей. | 29 дней | HTTP | ||||
| _/ad/75aa344edeef4dbfa3b3dd7cb5f40e6f/pixel | q.quora.com | Собирает данные о поведении и взаимодействии пользователей с целью оптимизации веб-сайта и повышения релевантности рекламы на веб-сайте. | Session | Pixel | ||||
| _fbp | regulaforensics.com | Используется Facebook для доставки ряда рекламных продуктов, таких как ставки в реальном времени от сторонних рекламодателей. | 3 месяца | HTTP | ||||
| _gcl_au | regulaforensics.com | Используется Google AdSense для экспериментов с эффективностью рекламы на веб-сайтах, использующих их услуги. | 3 месяца | HTTP | ||||
| _lfa | regulaforensics. com | Используется в контексте маркетинга на основе учетных записей (ABM). Файл cookie регистрирует такие данные, как IP-адреса, время, проведенное на веб-сайте, и запросы страниц для посещения. Это используется для ретаргетинга нескольких пользователей, использующих одни и те же IP-адреса. ABM обычно способствует маркетинговым целям B2B. | 399 дней | HTTP | ||||
| _lfa | regulaforensics.com | Используется в контексте маркетинга на основе учетных записей (ABM). Файл cookie регистрирует такие данные, как IP-адреса, время, проведенное на веб-сайте, и запросы страниц для посещения. Это используется для ретаргетинга нескольких пользователей, использующих одни и те же IP-адреса. ABM обычно способствует маркетинговым целям B2B. | Постоянный | HTML | ||||
| _lfa_expiry | regulaforensics.com | Содержит дату истечения срока действия файла cookie с соответствующим именем. | Постоянный | HTML | ||||
| _lfa_test_cookie_stored | regulaforensics. com | Используется в контексте маркетинга на основе учетных записей (ABM). Файл cookie регистрирует такие данные, как IP-адреса, время, проведенное на веб-сайте, и запросы страниц для посещения. Это используется для ретаргетинга нескольких пользователей, использующих одни и те же IP-адреса. ABM обычно способствует маркетинговым целям B2B. | 1 день | HTTP | ||||
| initialTrafficSource | regulaforensics.com | Регистрирует, как пользователь попал на веб-сайт, чтобы разрешить выплату реферальных комиссий партнерам. | 399 day | HTTP | ||||
| Unclassified | intercom-device-id-vbmpijy9 | regulaforensics.com | 270 day | HTTP | ||||
| Unclassified | regula_session | regulaforensics.com | 1 day | HTTP |
Cookies explore.regula.app
| Category | Name | Provider | Purpose | Validity | Type |
|---|---|---|---|---|---|
| Необходимо | test_cookie | doubleclick. net | Используется для проверки поддержки файлов cookie браузером пользователя. | 1 день | HTTP |
| CookieConsent | Explore.Regula.App | Сохраняет согласие пользователя. определить, принял ли посетитель окно согласия на использование файлов cookie. | Сеанс | HTTP | |
| li_gc | linkedin.com | Сохраняет состояние согласия пользователя на использование файлов cookie для текущего домена | 179 days | HTTP | |
| Preferences | lang | ads.linkedin.com | Remembers the user’s selected language version of a website | Session | HTTP |
| intercom.intercom-state-# | explore.regula.app | Запоминает, сворачивал ли пользователь или закрывал окно чата или всплывающие сообщения на веб-сайте. | Постоянный | HTML | |
| интерком-id-# | explore. regula.app | Позволяет веб-сайту узнавать посетителя, чтобы оптимизировать функциональность чата. | 270 дней | HTTP | |
| intercom-session-# | explore.regula.app | Устанавливает определенный идентификатор для пользователя, который обеспечивает целостность функции чата веб-сайта. | 6 дней | HTTP | |
| Статистика | c.gif | c.clarity.ms | Собирает данные о навигации и поведении пользователя на сайте. Это используется для составления статистических отчетов и тепловых карт для владельца сайта. | Сеанс | Пиксель |
| CLID | clear.ms | Собирает данные о навигации и поведении пользователя на веб-сайте. Это используется для составления статистических отчетов и тепловых карт для владельца сайта. | 1 год | HTTP | |
| __vw_tab_guid | explore.regula.app | Регистрирует данные о поведении посетителей на сайте. Это используется для внутреннего анализа и оптимизации сайта. | Сессия | HTML | |
| _cltk | explore.regula.app | Регистрирует статистические данные о поведении пользователей на сайте. Используется для внутренней аналитики оператором сайта. | Сеанс | HTML | |
| _ga | explore.regula.app | Регистрирует уникальный идентификатор, который используется для создания статистических данных о том, как посетитель использует веб-сайт. | 399 дней | HTTP | |
| _gat | explore.regula.app | Используется Google Analytics для регулирования частоты запросов | 1 день | HTTP | |
| _gid | explore.regula.app | Регистрирует уникальный идентификатор, который используется для создания статистических данных. посетитель использует веб-сайт. | 1 день | HTTP | |
| ln_or | explore. regula.app | Регистрирует статистические данные о поведении пользователей на сайте. Используется для внутренней аналитики оператором сайта. | 1 день | HTTP | |
| collect | google-analytics.com | Используется для отправки данных в Google Analytics об устройстве и поведении посетителя. Отслеживает посетителей по устройствам и маркетинговым каналам. | Сеанс | Пиксель | |
| __utmz | regula.app | Собирает данные о том, откуда пришел пользователь, какая поисковая система использовалась, какая ссылка была нажата и какой поисковый запрос был использован. Используется Google Analytics. | Сессия | HTTP | |
| _clck | regula.app | Собирает данные о навигации и поведении пользователя на веб-сайте. Это используется для составления статистических отчетов и тепловых карт для владельца сайта. | 1 год | HTTP | |
| _clsk | regula. app | Регистрирует статистические данные о поведении пользователей на сайте. Используется для внутренней аналитики оператором сайта. | 1 день | HTTP | |
| _ga | regula.app | Регистрирует уникальный идентификатор, который используется для создания статистических данных о том, как посетитель использует веб-сайт. | 399 дней | HTTP | |
| _ga_# | regula.app | Используется Google Analytics для сбора данных о том, сколько раз пользователь посещал веб-сайт, а также даты первого и последнего посещения. | 399 дней | HTTP | |
| _gat | regula.app | Используется Google Analytics для регулирования частоты запросов | 1 день | HTTP | |
| _gid | веб-сайт. | 1 день | HTTP | ||
| https://#.#/ | tr.lfeeder.com | Регистрирует статистические данные о поведении пользователей на сайте. Используется для внутренней аналитики оператором сайта. | Session | Pixel | |
| Marketing | MUID | bing.com | Широко используется Microsoft в качестве уникального идентификатора пользователя. Файл cookie позволяет отслеживать пользователей, синхронизируя идентификатор во многих доменах Microsoft. | 1 год | HTTP |
| SRM_B | bing.com | Отслеживает взаимодействие пользователя с функцией поиска веб-сайта. Эти данные могут быть использованы для предоставления пользователю соответствующих продуктов или услуг. | 1 день | HTTP | |
| ANONCHK | c.clarity.ms | Регистрирует данные о посетителях из нескольких посещений и на нескольких веб-сайтах. Эта информация используется для измерения эффективности рекламы на веб-сайтах. | 1 день | HTTP | |
| SM | c.clarity.ms | Регистрирует уникальный идентификатор, который идентифицирует устройство пользователя во время повторных посещений веб-сайтов, использующих ту же рекламную сеть. Идентификатор используется для разрешения целевой рекламы. | Сеанс | HTTP | |
| MUID | clear.ms | Широко используется корпорацией Майкрософт в качестве уникального идентификатора пользователя. Файл cookie позволяет отслеживать пользователей, синхронизируя идентификатор во многих доменах Microsoft. | 1 год | HTTP | |
| IDE | doubleclick.net | Используется Google DoubleClick для регистрации и отчета о действиях пользователя веб-сайта после просмотра или нажатия на одно из объявлений рекламодателя с целью измерения эффективности объявления и показывать пользователю таргетированную рекламу. | 1 год | HTTP | |
| pagead/landing | doubleclick.net | Собирает данные о поведении посетителей с нескольких веб-сайтов, чтобы показывать более релевантную рекламу. им показывают одну и ту же рекламу. | Session | Pixel | |
| _lfa | explore. regula.app | Используется в контексте маркетинга на основе учетных записей (ABM). Файл cookie регистрирует такие данные, как IP-адреса, время, проведенное на веб-сайте, и запросы страниц для посещения. Это используется для ретаргетинга нескольких пользователей, использующих одни и те же IP-адреса. ABM обычно способствует маркетинговым целям B2B. | Постоянный | HTML | |
| _lfa_expiry | explore.regula.app | Содержит дату истечения срока действия файла cookie с соответствующим именем. | Постоянный | HTML | |
| _lfa_test_cookie_stored | explore.regula.app | Используется в контексте маркетинга на основе учетных записей (ABM). Файл cookie регистрирует такие данные, как IP-адреса, время, проведенное на веб-сайте, и запросы страниц для посещения. Это используется для ретаргетинга нескольких пользователей, использующих одни и те же IP-адреса. ABM обычно способствует маркетинговым целям B2B. | 1 день | HTTP | |
| _uetsid | explore.regula.app | Используется для отслеживания посетителей на нескольких веб-сайтах с целью представления релевантной рекламы на основе предпочтений посетителя. | Постоянный | HTML | |
| _uetsid_exp | explore.regula.app | Содержит дату истечения срока действия файла cookie с соответствующим именем. | Постоянный | HTML | |
| _uetvid | explore.regula.app | Используется для отслеживания посетителей на нескольких веб-сайтах с целью представления релевантной рекламы на основе предпочтений посетителя. | Постоянный | HTML | |
| _uetvid_exp | explore.regula.app | Содержит дату истечения срока действия файла cookie с соответствующим именем. | Постоянный | HTML | |
| ads/ga-audiences | google.com | Используется Google AdWords для повторного привлечения посетителей, которые могут превратиться в клиентов на основе поведения посетителя на веб-сайтах. | Session | Pixel | |
| pagead/landing | google.com | Собирает данные о поведении посетителей с нескольких веб-сайтов, чтобы показывать более релевантную рекламу. показывают одну и ту же рекламу. | Session | Pixel | |
| bcookie | linkedin.com | Используется социальной сетью LinkedIn для отслеживания использования встроенных сервисов. | 1 год | HTTP | |
| lidc | linkedin.com | Используется социальной сетью LinkedIn для отслеживания использования встроенных сервисов. | 1 год | HTTP | |
| _/ad/75aa344edeef4dbfa3b3dd7cb5f40e6f/pixel | q.quora.com | Собирает данные о поведении пользователей и взаимодействии с ними на веб-сайте и делает его более релевантным для оптимизации рекламы и взаимодействия. | Сессия | Pixel | |
| _fbp | regula.app | Используется Facebook для доставки ряда рекламных продуктов, таких как ставки в реальном времени от сторонних рекламодателей. | 3 месяца | HTTP | |
| _gcl_au | regula.app | Используется Google AdSense для экспериментов с эффективностью рекламы на веб-сайтах, использующих их услуги. | 3 месяца | HTTP | |
| _lfa | regula.app | Используется в контексте маркетинга на основе учетных записей (ABM). Файл cookie регистрирует такие данные, как IP-адреса, время, проведенное на веб-сайте, и запросы страниц для посещения. Это используется для ретаргетинга нескольких пользователей, использующих одни и те же IP-адреса. ABM обычно способствует маркетинговым целям B2B. | 399 дней | HTTP | |
| _lfa_test_cookie_stored | regula.app | Используется в контексте маркетинга на основе учетных записей (ABM). Файл cookie регистрирует такие данные, как IP-адреса, время, проведенное на веб-сайте, и запросы страниц для посещения. Это используется для ретаргетинга нескольких пользователей, использующих одни и те же IP-адреса. ABM обычно способствует маркетинговым целям B2B. | 1 день | HTTP | |
| _uetsid | regula.app | Собирает данные о поведении посетителей с нескольких веб-сайтов, чтобы показывать более релевантную рекламу. показали ту же рекламу. | 1 день | HTML | |
| _uetvid | regula.app | Используется для отслеживания посетителей на нескольких веб-сайтах с целью представления релевантной рекламы на основе предпочтений посетителя. | 1 год | HTTP | |
| initialTrafficSource | regula.app | Регистрирует, как пользователь попал на веб-сайт, чтобы разрешить выплату реферальных комиссий партнерам. | 399 days | HTTP | |
| Unclassified | intercom-device-id-vbmpijy9 | explore.regula.app | 270 day | HTTP |
Cookies api.regulaforensics.com
| Category | Name | Provider | Purpose | Validity | Type |
|---|---|---|---|---|---|
| Necessary | CookieConsent | api. regulaforensics.com | Stores the user’s cookie consent state for the current домен | 1 год | HTTP |
| cookietest | api.regulaforensics.com | Этот файл cookie используется для определения того, принял ли посетитель окно согласия на использование файлов cookie. | Сеанс | HTTP | |
| test_cookie | doubleclick.net | Используется для проверки поддержки файлов cookie браузером пользователя. | 1 day | HTTP | |
| li_gc | linkedin.com | Stores the user’s cookie consent state for the current domain | 179 days | HTTP | |
| Preferences | lang | ads.linkedin. com | Запоминает выбранную пользователем языковую версию веб-сайта | Session | HTTP |
| intercom.intercom-state-# | api.regulaforensics.com | Запоминает, сворачивал ли пользователь или закрывал окно чата или всплывающие окна на веб-сайте. | Постоянный | HTML | |
| intercom-id-# | api.regulaforensics.com | Позволяет веб-сайту узнавать посетителя, чтобы оптимизировать функциональность чата. | 270 дней | HTTP | |
| intercom-session-# | api.regulaforensics.com | Устанавливает конкретный идентификатор для пользователя, который обеспечивает целостность функции чата на веб-сайте. | 6 дней | HTTP | |
| Статистика | _cltk | api.regulaforensics.com | Регистрирует статистические данные о поведении пользователей на сайте. Используется для внутренней аналитики оператором сайта. | Сеанс | HTML |
| _ga | api.regulaforensics.com | Регистрирует уникальный идентификатор, который используется для создания статистических данных о том, как посетитель использует веб-сайт. | 399 days | HTTP | |
| _gat | api. regulaforensics.com | Used by Google Analytics to throttle request rate | 1 day | HTTP | |
| _gid | api.regulaforensics.com | Регистрирует уникальный идентификатор, который используется для создания статистических данных о том, как посетитель использует веб-сайт. | 1 день | HTTP | |
| c.gif | c.clarity.ms | Собирает данные о навигации и поведении пользователя на веб-сайте. Это используется для составления статистических отчетов и тепловых карт для владельца сайта. | Сессия | Пиксель | |
| CLID | clear.ms | Собирает данные о навигации и поведении пользователя на веб-сайте. Это используется для составления статистических отчетов и тепловых карт для владельца сайта. | 1 год | HTTP | |
| collect | google-analytics.com | Используется для отправки данных в Google Analytics об устройстве и поведении посетителя. Отслеживает посетителей по устройствам и маркетинговым каналам. | Session | Pixel | |
| AnalyticsSyncHistory | linkedin.com | Используется в связи с синхронизацией данных со сторонней аналитической службой. | 29 дней | HTTP | |
| __utmz | regulaforensics.com | Собирает данные о том, откуда пришел пользователь, какая поисковая система использовалась, какая ссылка была нажата и какой поисковый запрос был использован. Используется Google Analytics. | Сеанс | HTTP | |
| _clck | regulaforensics.com | Собирает данные о навигации и поведении пользователя на веб-сайте. Это используется для составления статистических отчетов и тепловых карт для владельца сайта. | 1 год | HTTP | |
| _clsk | regulaforensics.com | Регистрирует статистические данные о поведении пользователей на сайте. Используется для внутренней аналитики оператором сайта. | 1 день | HTTP | |
| _cltk | regulaforensics.com | Регистрирует статистические данные о поведении пользователей на сайте. Используется для внутренней аналитики оператором сайта. | Сеанс | HTML | |
| _ga | regulaforensics.com | Регистрирует уникальный идентификатор, который используется для создания статистических данных о том, как посетитель использует веб-сайт. | 399 дней | HTTP | |
| _ga_# | regulaforensics.com | Используется Google Analytics для сбора данных о том, сколько раз пользователь посещал веб-сайт, а также о датах первого и последнего посещения. | 399 дней | HTTP | |
| _gat | regulaforensics.com | Используется Google Analytics для регулирования частоты запросов | 1 день | HTTP | |
| _gid | веб-сайт. | 1 день | HTTP | ||
| Маркетинг | SRM_B | bing. com | Отслеживает взаимодействие пользователя с функцией поиска веб-сайта. Эти данные могут быть использованы для предоставления пользователю соответствующих продуктов или услуг. | 1 год | HTTP |
| ANONCHK | c.clarity.ms | Регистрирует данные о посетителях из нескольких посещений и на нескольких веб-сайтах. Эта информация используется для измерения эффективности рекламы на веб-сайтах. | 1 день | HTTP | |
| SM | c.clarity.ms | Регистрирует уникальный идентификатор, который идентифицирует устройство пользователя во время повторных посещений веб-сайтов, использующих ту же рекламную сеть. Идентификатор используется для разрешения целевой рекламы. | Сеанс | HTTP | |
| MUID | clear.ms | Широко используется корпорацией Майкрософт в качестве уникального идентификатора пользователя. Файл cookie позволяет отслеживать пользователей, синхронизируя идентификатор во многих доменах Microsoft. | 1 год | HTTP | |
| IDE | doubleclick.net | Используется Google DoubleClick для регистрации и отчета о действиях пользователя веб-сайта после просмотра или нажатия на одно из объявлений рекламодателя с целью измерения эффективности объявления и показывать пользователю таргетированную рекламу. | 1 год | HTTP | |
| pagead/landing | doubleclick.net | Собирает данные о поведении посетителей с нескольких веб-сайтов, чтобы показывать более релевантную рекламу. им показывают одну и ту же рекламу. | Сеанс | Пиксель | |
| ads/ga-audiences | google.com | Используется Google AdWords для повторного привлечения посетителей, которые могут превратиться в клиентов на основе поведения посетителя на веб-сайтах. | Session | Pixel | |
| pagead/landing | google.com | Собирает данные о поведении посетителей с нескольких веб-сайтов, чтобы показывать более релевантную рекламу. показывают одну и ту же рекламу. | Session | Pixel | |
| bcookie | linkedin.com | Используется социальной сетью LinkedIn для отслеживания использования встроенных сервисов. | 1 год | HTTP | |
| bscookie | linkedin.com | Используется социальной сетью LinkedIn для отслеживания использования встроенных сервисов. | 1 год | HTTP | |
| язык | linkedin.com | Устанавливается LinkedIn, когда веб-страница содержит встроенную панель «Подпишитесь на нас». | Сеанс | HTTP | |
| lidc | linkedin.com | Используется социальной сетью LinkedIn для отслеживания использования встроенных сервисов. | 1 день | HTTP | |
| UserMatchHistory | linkedin.com | Обеспечивает безопасность навигации посетителей, предотвращая подделку межсайтовых запросов. Этот файл cookie необходим для безопасности веб-сайта и посетителей. | 29 дней | HTTP | |
| _/ad/75aa344edeef4dbfa3b3dd7cb5f40e6f/pixel | q.quora.com | Собирает данные о поведении пользователей и делает их более релевантными для оптимизации рекламы и взаимодействия на веб-сайте. | Session | Pixel | |
| _fbp | regulaforensics.com | Используется Facebook для доставки ряда рекламных продуктов, таких как ставки в реальном времени от сторонних рекламодателей. | 3 месяца | HTTP | |
| _gcl_au | regulaforensics.com | Используется Google AdSense для экспериментов с эффективностью рекламы на веб-сайтах, использующих их услуги. | 3 месяца | HTTP | |
| initialTrafficSource | regulaforensics.com | Регистрирует, как пользователь попал на веб-сайт, чтобы разрешить выплату комиссионных за рефералов партнерам. | 399 day | HTTP | |
| Unclassified | HCLBSTICKY | api. regulaforensics.com | Session | HTTP | |
| intercom-device-id-vbmpijy9 | api.regulaforensics.com | 270 день | HTTP | ||
| v | api.regulaforensics.com | Persistent | HTML |
Cookies faceapi.regulaforensics.com
| Category | Name | Provider | Purpose | Срок действия | Тип | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Необходимо | test_cookie | doubleclick.net | Используется для проверки поддержки файлов cookie браузером пользователя. | 1 day | HTTP | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| CookieConsent | faceapi.regulaforensics.com | Stores the user’s cookie consent state for the current domain | 1 year | HTTP | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| cookietest | faceapi. regulaforensics.com | Этот файл cookie используется для определения того, принял ли посетитель окно согласия на использование файлов cookie. | Сессия | HTTP | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| li_gc | linkedin.com | Stores the user’s cookie consent state for the current domain | 179 days | HTTP | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Preferences | lang | ads.linkedin.com | Remembers the user’s selected language version of a website | Session | HTTP | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| intercom.intercom-state-# | faceapi.regulaforensics.com | Запоминает, свернул ли пользователь или закрыл окно чата или всплывающие сообщения на веб-сайте. | Постоянный | HTML | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| intercom-id-# | faceapi.regulaforensics.com | Позволяет веб-сайту узнавать посетителя, чтобы оптимизировать функциональность чата. | 270 дней | HTTP | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| intercom-session-# | faceapi. regulaforensics.com | Устанавливает определенный идентификатор для пользователя, который обеспечивает целостность функции чата веб-сайта. | 6 дней | HTTP | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Статистика | c.gif | c.clarity.ms | Собирает данные о навигации и поведении пользователя на веб-сайте. Это используется для составления статистических отчетов и тепловых карт для владельца сайта. | Сессия | Пиксель | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| CLID | clear.ms | Собирает данные о навигации и поведении пользователя на веб-сайте. Это используется для составления статистических отчетов и тепловых карт для владельца сайта. | 1 год | HTTP | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| _cltk | faceapi.regulaforensics.com | Регистрирует статистические данные о поведении пользователей на сайте. Используется для внутренней аналитики оператором сайта. | Сеанс | HTML | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| _ga | faceapi. regulaforensics.com | Регистрирует уникальный идентификатор, который используется для создания статистических данных о том, как посетитель использует веб-сайт. | 399 дней | HTTP | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| _gat | faceapi.regulaforensics.com | Used by Google Analytics to throttle request rate | 1 day | HTTP | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| _gid | api.regulaforensics.com | Registers a unique ID that is used для создания статистических данных о том, как посетитель использует веб-сайт. | 1 день | HTTP | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| collect | google-analytics.com | Используется для отправки данных в Google Analytics об устройстве и поведении посетителя. Отслеживает посетителей по устройствам и маркетинговым каналам. | Session | Pixel | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| AnalyticsSyncHistory | linkedin.com | Используется в связи с синхронизацией данных со сторонней службой анализа. | 29 дней | HTTP | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| __utmz | regulaforensics.com | Собирает данные о том, откуда пришел пользователь, какая поисковая система использовалась, какая ссылка была нажата и какой поисковый запрос был использован. Используется Google Analytics. | Сеанс | HTTP | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| _clck | regulaforensics.com | Собирает данные о навигации и поведении пользователя на веб-сайте. Это используется для составления статистических отчетов и тепловых карт для владельца сайта. | 1 год | HTTP | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| _clsk | regulaforensics.com | Регистрирует статистические данные о поведении пользователей на сайте. Используется для внутренней аналитики оператором сайта. | 1 день | HTTP | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| _ga | regulaforensics.com | Регистрирует уникальный идентификатор, который используется для создания статистических данных о том, как посетитель использует веб-сайт. | 399 дней | HTTP | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| _ga_# | regulaforensics.com | Используется Google Analytics для сбора данных о том, сколько раз пользователь посещал веб-сайт, а также о датах первого и последнего посещения. | 399 дней | HTTP | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| _gat | regulaforensics.com | Используется Google Analytics для запроса на дроссель | 1 день | http | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
_GID
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||